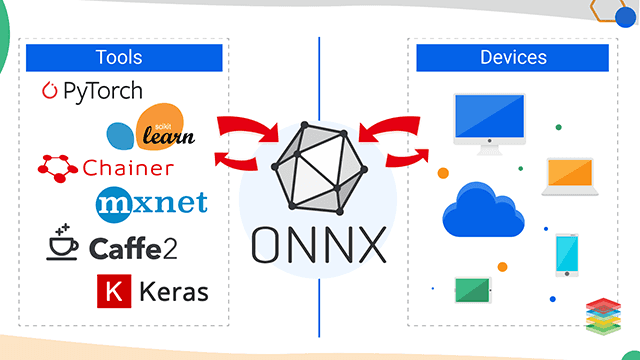
ONNX
ONNX 可以理解为机器学习模型的中间表示格式:训练时可以用 PyTorch、TensorFlow、scikit-learn 等框架,部署时把模型导出成 .onnx,再交给 ONNX Runtime、TensorRT、OpenVINO、CoreML、DirectML 等后端执行。

1. ONNX 是什么
ONNX,全称 Open Neural Network Exchange,是一个开放的 AI 模型格式。它定义了三类核心内容:计算图模型、内置算子、标准数据类型;官方也明确说当前重点主要是 inference/scoring,而不是完整训练框架替代品。(GitHub)
一句话概括:
ONNX 是模型交换格式和推理部署 IR。
典型链路是:
1 | PyTorch / TensorFlow / sklearn |
它解决的问题是:训练框架与部署后端解耦。不一定要在生产环境里安装完整 PyTorch;可以把模型固化成 ONNX 图,然后用更轻量、更接近硬件的 runtime 执行。
2. .onnx 文件里面有什么
.onnx 本质上是一个 protobuf 序列化文件,核心对象是 ModelProto。可以把它理解成:
1 | ModelProto |
最关键的是 graph。ONNX 图由节点、边、输入、输出、权重常量组成。每个 node 调用一个 operator,例如 Conv、Relu、MatMul、LayerNormalization、Gather、Softmax。节点通过名字连接:一个节点的输出名可以成为后续节点的输入名。官方 IR 规范要求图中 node output 遵循 single static assignment,也就是每个输出名在同一图内唯一;节点依赖不能形成环;顶层节点列表需要按拓扑顺序排列。(ONNX)
几个重要字段:
input 是模型对外暴露的输入,例如 pixel_values、input_ids、attention_mask。
output 是模型对外暴露的输出,例如 logits、last_hidden_state、embeddings。
initializer 通常存模型权重,比如卷积核、Linear 层权重、bias、LayerNorm 参数。官方规范也说明,若一个名字同时出现在 initializer 和 graph input 中,runtime 可以允许调用者覆盖该值;不希望被调用者覆盖的常量应只放在 initializer 中。(ONNX)
node 是计算步骤。每个 node 主要包含 op_type、domain、input、output、attribute。其中 op_type 是算子名,attribute 是静态参数,例如 Conv 的 kernel_shape、pads、strides。(ONNX)
3. ONNX Graph 的直观例子
一个简单 CNN 导出后可能类似这样:
1 | input |
这里 Conv、Relu、MaxPool、Flatten、Gemm、Softmax 是 ONNX operators;W1、b1、W2、b2 多半存在 initializer 里。
对 Transformer 来说,ONNX 图会更大,常见节点包括:
1 | Gather / Shape / Reshape / Transpose / MatMul / Add / Softmax / LayerNormalization / Cast / Slice / Concat |
多模态模型导出后也通常拆成多个 ONNX:例如 vision encoder 一个 ONNX,text encoder 一个 ONNX,fusion/head 一个 ONNX。这样更容易做缓存、并行、量化和跨设备部署。
4. Opset 是什么
opset 是 ONNX 里非常关键的版本机制。它不是 ONNX 包版本,而是算子集合版本。同一个算子在不同 opset 下,输入、属性、类型约束、广播规则、边界行为可能不同。官方 operator 文档会列出每个算子的参数、示例和逐版本变化历史。(ONNX)
例如:
1 | opset_import: ai.onnx version 17 |
表示这个模型使用 ai.onnx domain 下第 17 版算子语义。
实践里经常遇到的问题是:
1 | 导出端支持 opset 18 |
所以导出 ONNX 时,不能只看能不能导出成功,还要确认目标 runtime 支持哪些 opset 和哪些 operator kernel。
5. ONNX Runtime 的执行方式
ONNX Runtime 是最常用的 ONNX 推理引擎之一。它通过 Execution Provider,简称 EP,把图中的节点或子图分配给不同硬件后端执行。官方文档说明,EP 机制用于对接 CPU、GPU、FPGA、NPU 等硬件加速库,并且 provider 列表有优先级;例如 ['CUDAExecutionProvider', 'CPUExecutionProvider'] 表示 CUDA 能跑的节点优先跑 CUDA,不能跑的回退到 CPU。(ONNX Runtime)
典型 Python 推理代码:
1 | import onnxruntime as ort |
这里 session.run(None, inputs) 表示取所有模型输出。如果只想取某些输出,可以把 None 换成输出名列表。
6. PyTorch 导出 ONNX
PyTorch 官方当前推荐的基础形式是使用 torch.onnx.export(..., dynamo=True) 导出 ONNX。(PyTorch Documentation)
示例:
1 | import torch |
关键点:
model.eval() 必须做,否则 Dropout、BatchNorm 等行为可能仍处于训练模式。
dummy 决定导出时的 tracing/example input 形状。
dynamic_axes 用于支持动态 batch 或动态序列长度。不设置时,很多维度会被固化。
opset_version 要根据目标 runtime 选择,不是越新越好。
dynamo=True 是 PyTorch 新导出路径的一部分,但具体可用性仍受 PyTorch 版本、模型结构和算子覆盖影响。
7. 验证和检查 ONNX
导出后建议至少做三件事:
1 | import onnx |
check_model 检查结构是否合法。
shape_inference 尝试补全中间 tensor 的 shape/type 信息,便于调试和后续优化。
然后做数值对齐:
1 | # 比较 PyTorch 输出与 ONNX Runtime 输出 |
对于分类模型,通常看 logits 最大差异、top-k 是否一致。对于 embedding 模型,建议看 cosine similarity。对于检测、分割、生成模型,要检查后处理是否也被包含在 ONNX 图中。
8. ONNX 优化
ONNX Runtime 支持图优化。官方文档把图优化描述为图级转换,范围从简单图简化、节点消除,到更复杂的节点融合和 layout 优化。(ONNX Runtime)
常见优化包括:
1 | Constant Folding 常量折叠 |
ONNX Runtime 也提供 8-bit 量化 API,包括预处理、动态量化、静态量化和量化调试。(ONNX Runtime)
粗略选择:
1 | CPU 推理:优先试 INT8 dynamic quantization,尤其是 Linear-heavy 模型。 |
9. ONNX 的优点
ONNX 的核心优点是部署中立。训练框架可以和推理后端分离,生产环境不必绑定 PyTorch 或 TensorFlow。官方也强调 ONNX 的目标之一是让开发者在不同框架、工具、runtime 和 compiler 之间使用模型。(ONNX)
它也适合性能优化。ONNX 图是静态图,更容易做子图融合、常量折叠、算子替换、量化和硬件编译。
它适合跨语言部署。Python 训练,C++/C#/Java/Node/mobile 侧推理都更方便。
它适合边缘端。很多芯片厂商和推理加速库会优先支持 ONNX 或 ONNX-like IR。
10. ONNX 的局限
ONNX 不是万能格式。最常见的问题是:
第一,动态图和控制流不一定好导。PyTorch 里的 Python 控制流、动态 shape、复杂 list/dict 操作、自定义 op,导出时可能失败或语义变化。
第二,算子支持不完全。模型能导出,不代表目标 runtime 能跑。比如 ONNX Runtime CPU 能跑,不代表 TensorRT EP 或某个 NPU SDK 能跑。
第三,前后处理容易遗漏。Tokenizer、image resize、NMS、decode、postprocess 经常在模型外部。如果部署端没有复刻一致,结果会偏。
第四,数值不一定完全一致。不同 kernel、融合、精度、量化、layout 都可能引入差异。部署前必须做端到端数值回归。
第五,大模型导出会遇到外部权重、动态 KV cache、算子覆盖、显存峰值、图过大等问题。LLM 或多模态大模型通常需要专门导出脚本和 runtime 优化,而不是简单 torch.onnx.export 一步完成。
11. 在多模态 RAG 中怎么用
如果是多模态 RAG,ONNX 通常用于这些位置:
1 | image encoder CLIP / SigLIP / ViT encoder |
典型架构:
1 | PDF / Image / Video / Audio frame |
对 RAG 系统而言,ONNX 的价值主要是:
1 | 降低推理依赖 |
12. 实战排错清单
遇到 ONNX 问题时,按这个顺序查:
1 | 1. onnx.checker.check_model 是否通过 |
1 | import torch |
13. 最小心智模型
把 ONNX 记成这三层就够了:
1 | ONNX = 静态计算图 + 标准算子语义 + 可移植权重容器 |
部署时真正执行它的是 runtime/compiler:
1 | ONNX file 只是模型描述 |
工程上最重要的不是“成功导出”,而是:
1 | 导出成功 |