
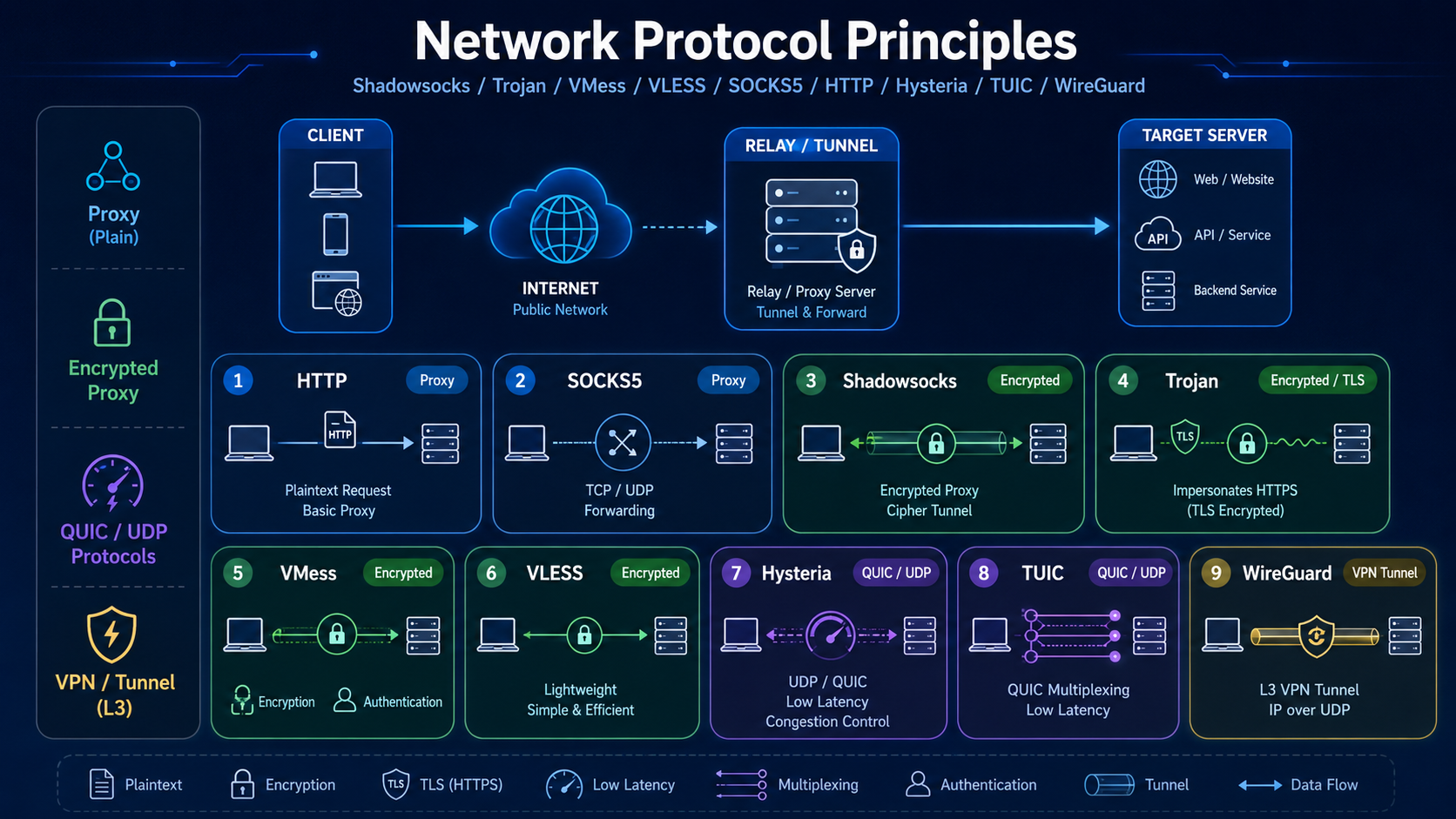
Clash 的运行原理(2):实例和各种代理协议
1. 一次 HTTPS 请求在 Clash 中的完整生命周期以访问 https://www.google.com 为例。 第一步:应用发起 DNS 查询浏览器要访问: 1www.google.com 它先请求 DNS 解析。 第二步:Clash DNS 返回 fake-ip如果开启 fake-ip,Clash 可能返回: 1www.google.com → 198.18.0.23 同时 Clash 记录映射: 1198.18.0.23 → www.google.com 第三步:浏览器连接 fake-ip浏览器以为 198.18.0.23 就是目标地址,于是建立 TCP 连接。 第四步:连接进入 Clash由于系统代理、TUN 或透明代理规则,这条连接进入 Clash。Clash 查映射表,知道: 1198.18.0.23 实际对应 www.google.com 第五步:规则匹配Clash 检查规则: 1- DOMAIN-SUFFIX,google.com,PROXY 命中后,决定走 PROXY 策略组。 第六步:策略组选择节点假设当前 PROXY 选择的是...
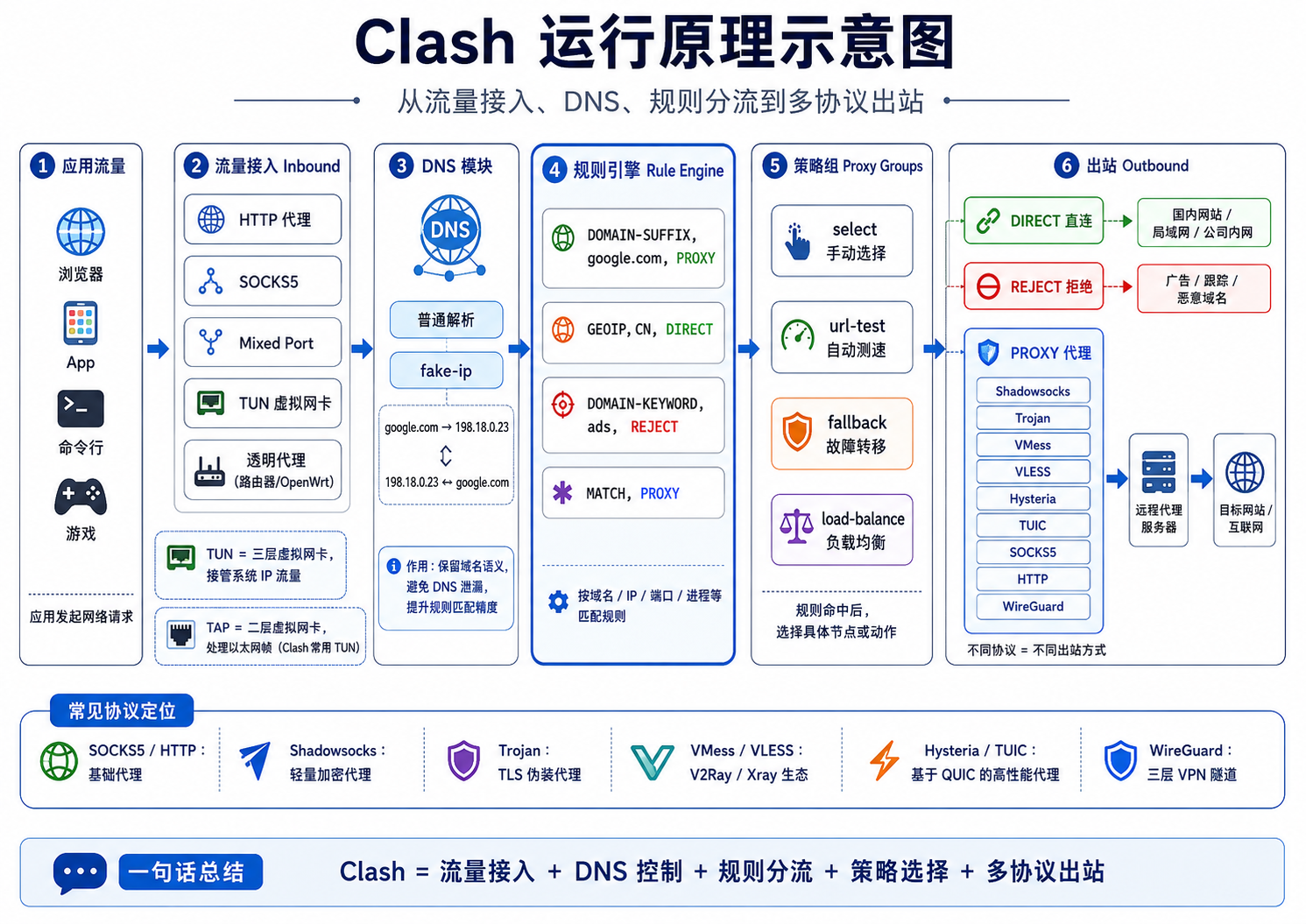
Clash 的运行原理(1):从虚拟网卡到 DNS 分流
Clash 的运行原理:从虚拟网卡到 DNS 分流 摘要Clash 是一个运行在本机或网关上的规则化代理转发引擎。它把应用程序或系统网络栈产生的流量接入本地,再通过 DNS 模块、规则引擎和策略组判断流量应该直连、拒绝,还是通过某个远程代理节点转发出去。 Clash 可以理解为以下几个模块的组合: 123456流量入口 Inbound+ DNS 解析与 fake-ip 映射+ 规则匹配引擎+ 策略组选择器+ 多协议出站 Outbound+ 远程代理服务器或直连出口 它和传统 VPN 的主要区别在于:传统 VPN 通常把整台设备的 IP 流量放进一个加密隧道,而 Clash 更强调按规则分流。同一台设备上,国内网站可以直连,海外网站可以走代理,广告域名可以拒绝,公司内网可以走 WireGuard,游戏 UDP 可以走 Hysteria 或 TUIC。Clash 的价值是把复杂网络流量按域名、IP、端口、进程、地理位置和协议特征进行精细路由。 1. 先区分几个概念:VPN、代理、Clash日常语境里,很多人会把 Clash、Trojan、Shadowsocks、VLESS...
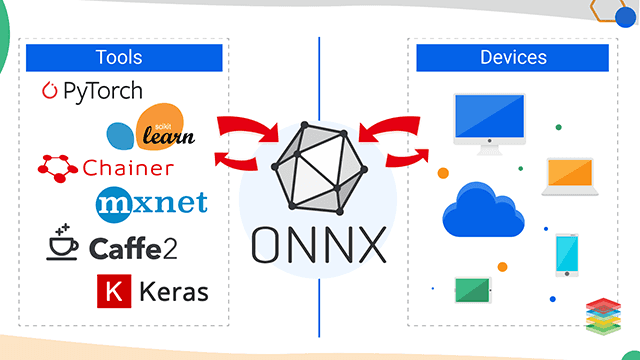
ONNX
ONNX 可以理解为机器学习模型的中间表示格式:训练时可以用 PyTorch、TensorFlow、scikit-learn 等框架,部署时把模型导出成 .onnx,再交给 ONNX Runtime、TensorRT、OpenVINO、CoreML、DirectML 等后端执行。 1. ONNX 是什么ONNX,全称 Open Neural Network Exchange,是一个开放的 AI 模型格式。它定义了三类核心内容:计算图模型、内置算子、标准数据类型;官方也明确说当前重点主要是 inference/scoring,而不是完整训练框架替代品。(GitHub) 一句话概括: ONNX 是模型交换格式和推理部署 IR。 典型链路是: 1234567PyTorch / TensorFlow / sklearn ↓ export / convert model.onnx ↓ runtime / compilerONNX Runtime / TensorRT / OpenVINO / CoreML / TVM / custom...
融合算子
融合算子本质上是:把计算图中多个连续的小算子合并成一个更大的算子或一个 GPU kernel,让它们一次性执行,减少中间结果写回显存、减少 kernel launch、减少 layout 转换,从而提高推理性能。 在 TensorRT、TVM、XLA、TorchInductor、ONNX Runtime、TensorRT-LLM 里,算子融合都是核心优化。 1. 为什么要融合算子GPU 推理不只是“算力瓶颈”,很多时候是: 1读显存 → 算一点 → 写显存 → 再读显存 → 再算一点 → 再写显存 例如: 1Conv → BatchNorm → ReLU 如果不融合,大概是: 12345678910111213kernel 1: Conv input 从显存读入 weight 从显存读入 conv 输出写回显存kernel 2: BatchNorm conv 输出再从显存读入 BN 参数读入 BN 输出写回显存kernel 3: ReLU BN 输出再从显存读入 ReLU 输出写回显存 问题有两个: 第一,中间 tensor 反复读写显存。第二,每个...
GEMM
GEMM 是 General Matrix Multiply,中文通常叫通用矩阵乘法。它是深度学习里最核心的计算形式之一。 它的标准形式是: C = \alpha A B + \beta C 其中: 1234A: m × k 矩阵B: k × n 矩阵C: m × n 矩阵α, β: 标量 如果忽略 $\alpha$、$\beta$,最常见的理解就是: 1C = A @ B 也就是矩阵乘矩阵。 1. GEMM 为什么重要神经网络里的很多算子,最后都可以转成 GEMM。 例如全连接层 / Linear 层: 1y = x @ W + b 如果: 12x: batch × hiddenW: hidden × output 那么: 1y: batch × output 这本质就是 GEMM,加上一个 bias。 Transformer 里的 Q、K、V 投影也是 GEMM: 123Q = X @ WqK = X @ WkV = X @ Wv MLP 也是 GEMM: 12H = GELU(X @ W1 + b1)Y = H @ W2 +...
用 Python 解释 Haskell Monad
假设你已经会使用一门简单的编程语言 Python 从一个具体问题开始你写过这种代码吗: 123456789user = get_user(id)if user is None: return Noneprofile = get_profile(user)if profile is None: return Nonescore = get_score(profile)if score is None: return None 每一步都可能失败,所以每一步之后都要检查。这段代码的真实逻辑只有三行,但被错误处理淹没了。 Monad 要解决的正是这类问题 如何把”带有某种额外语境的计算”优雅地串联起来。 三个层次来理解第一层:Monad 是一种设计模式 先忘掉范畴论。Monad 就是一个包装盒,加上两个操作: return(或 pure):把一个普通值放进盒子 >>=(bind):把盒子里的值取出来,交给下一个函数,返回新的盒子 12普通值 → return → [盒子][盒子] → >>= f → ...
文本相似度计算
文本相似度计算 基准方法:文本->词->嵌入->平均池化->余弦相似度 Word Mover’s Distance rank_bm25 无监督短文本匹配1. TF-IDF Term Frequency-Inverse Document FrequencyTF-IDF(Term Frequency-Inverse Document Frequency)是一种在信息检索和文本挖掘中广泛使用的加权技术,用于评估一个词在一个文档或语料库中的重要性。TF-IDF算法结合了两个统计测量:词频(TF)和逆文档频率(IDF),来计算一个词的权重。 词频(TF, Term Frequency) 词频是指一个词在文档中出现的频率。一个词在文档中出现得越频繁,其TF值就越高,表明这个词对该文档的内容可能越重要。然而,仅仅使用词频作为权重是有缺陷的,因为常见的词汇(如冠词、介词等)会获得较高的权重,尽管它们对于文档的主题贡献不大。 TF的计算公式可以表示为:$$ \text{TF}(t, d) = \frac{\text{词 } t \text{ 在文档 } d...
PG Vector
Getting StartedEnable the extension (do this once in each database where you want to use it) 1CREATE EXTENSION vector; Create a vector column with 3 dimensions 1CREATE TABLE items (id bigserial PRIMARY KEY, embedding vector(3)); Insert vectors 1INSERT INTO items (embedding) VALUES ('[1,2,3]'), ('[4,5,6]'); Get the nearest neighbors by L2 distance 1SELECT * FROM items ORDER BY embedding <-> '[3,1,2]' LIMIT 5; Also supports inner product (<#>) and...
Gen AI
虽然 LLM 提供了很大的潜力,但你也应该谨慎。 LLM 的核心是经过训练来预测序列中的以下单词。 这些单词基于训练数据中其他文本的模式和关系。这些训练数据的来源通常是互联网、书籍和其他公开可用的文本。这些数据的质量可能有问题,也可能是不正确的。培训发生在某个时间点,它可能无法反映世界的当前状态,也不会包含任何私人信息。 LLM 经过微调以尽可能有用,即使这意味着偶尔会产生误导性或毫无根据的内容,这种现象称为幻觉。 例如,当被要求“描述月亮”时,LLM可能会回答“月亮是由奶酪制成的”。虽然这是一句俗语,但事实并非如此。 修复幻觉提供额外的上下文数据有助于为 LLM 的响应奠定基础并使其更加准确。 知识图谱是一种向 LLM 提供额外数据的机制。知识图谱中的数据可以指导 LLM 提供更相关、更准确和更可靠的响应。 虽然LLM使用其语言技能来解释和响应上下文数据,但它不会忽视原始训练数据。 您可以将原始训练数据视为基础知识和语言能力,而上下文信息则在特定情况下提供指导。 这两种方法的结合使 LLM 能够产生更有意义的响应。 避免幻觉LLM 可以“编造”。LLM...
概率论
条件概率是指在给定某个条件下,某个事件发生的概率。用于描述事件之间的依赖关系。假设我们有两个事件 A 和 B,其中事件 A 是我们感兴趣的事件,事件 B 是某个条件。条件概率表示在已知事件 B 发生的情况下,事件 A 发生的概率,记作 $P(A|B)$。 条件概率的计算公式如下: $$ P(A|B) = \frac{P(A \cap B)}{P(B)} $$ 其中,$P(A \cap B)$ 表示事件 A 和事件 B 同时发生的概率,称为事件 A 与事件 B 的交集。$P(B)$ 表示事件 B 发生的概率。 条件概率的计算可以通过已知的概率和事件之间的关系来进行推导。它可以帮助我们理解事件之间的依赖关系,并在实际问题中进行推断和决策。 条件概率在很多领域都有广泛的应用,例如在机器学习中,条件概率可以用于建模和分类;在信息论中,条件概率可以用于计算熵和互信息等。 需要注意的是,条件概率的计算需要满足一些前提条件,例如事件 B 的概率不能为零,事件 A 和事件 B 之间应该是独立或有一定的关联性等。...